Data Source Management for Capture Fields
Introduction
Capture fields are prompts presented during an MFD workflow (for example Quick Scan), that users complete to provide extra information about the job they are processing. There are various types of Capture Fields (Text, Dropdown, and Data Source Lookup). The Data Source Management APIs are concerned with the Data Source Lookup Capture Fields.
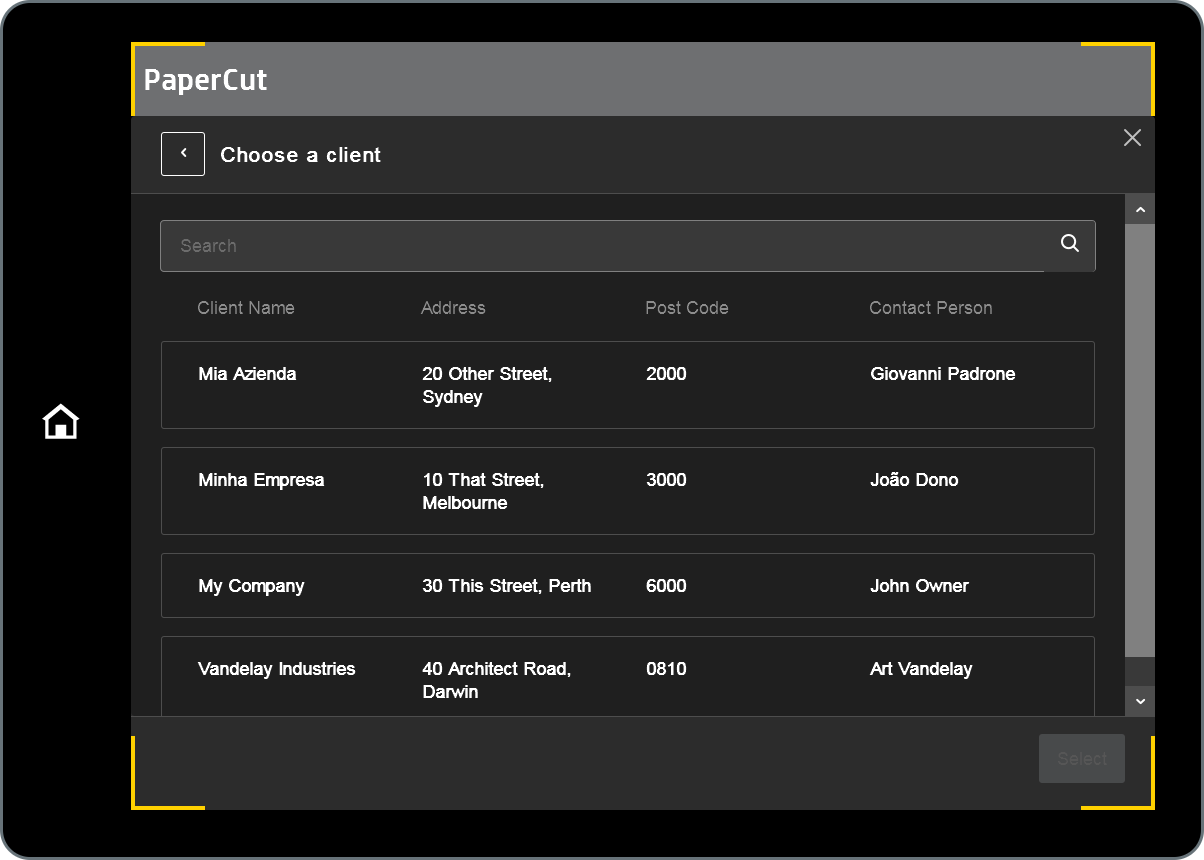
Capture fields are managed by admins when they create the Quick Scan, the data content of the lookups are managed via the Data Source Management APIs, as described here.
There is more information about capture fields here.
High-level workflow to set up a Quick Scan with Data Source Lookup fields
These are the main steps for how a lookup field is created and used.
- The add-on solution uses the PaperCut Hive API to import a CSV/TSV file into PaperCut Hive.
- The customer admin creates a Quick Scan with one or more Data Source Lookup fields that point to the imported data source
- The end-user starts scanning a document at the MFD. In the lookup field(s), they select the data they need by searching the data the admin linked to that Quick Scan.
- PaperCut Hive sends the scan file and metadata to the scan destination using the data capture webhook
- The add-on solution can update the contents of the Data Source via the API as needed, for example when a new matter is added in a legal case management system.
Adding a New Data Source
- Call the
Get upload URLendpoint to obtain an upload URL and file ID - Stream data to the upload URL via an https PUT
- Call the
Import Dataendpoint with the file ID from step 1 - The PaperCut Hive admin must now configure any desired Data Source Lookup Capture Fields
Updating a Data Source’s Data
- You’ll need the file ID value from the initial upload (same as Data Source ID).
- Call the
Get upload URLendpoint to obtain an upload URL and new file ID - Ignore the new file ID
- Stream data to the upload URL via an https PUT
- Call the Import Data endpoint using the file ID from step 1
Further information
Please see the fine API reference